Internal Replication setting in ClickHouse
Table of Contents
There are two option for internal_replication setting in ClickHouse:
internal_replication = true
This option is useful when you’re using Replicated tables and insert data into Distributed table (most of cases). The Distributed table inserts data only into one of underlying table replicas, after that the Replicated table replicates data into other replicas.
internal_replication = false (default)
This option can be useful when you’re using non-Replicated tables and insert data into Distributed table. Writes down data to all underlying replicas if we do insert in a Distributed table. In this case, the Distributed table replicates data itself.
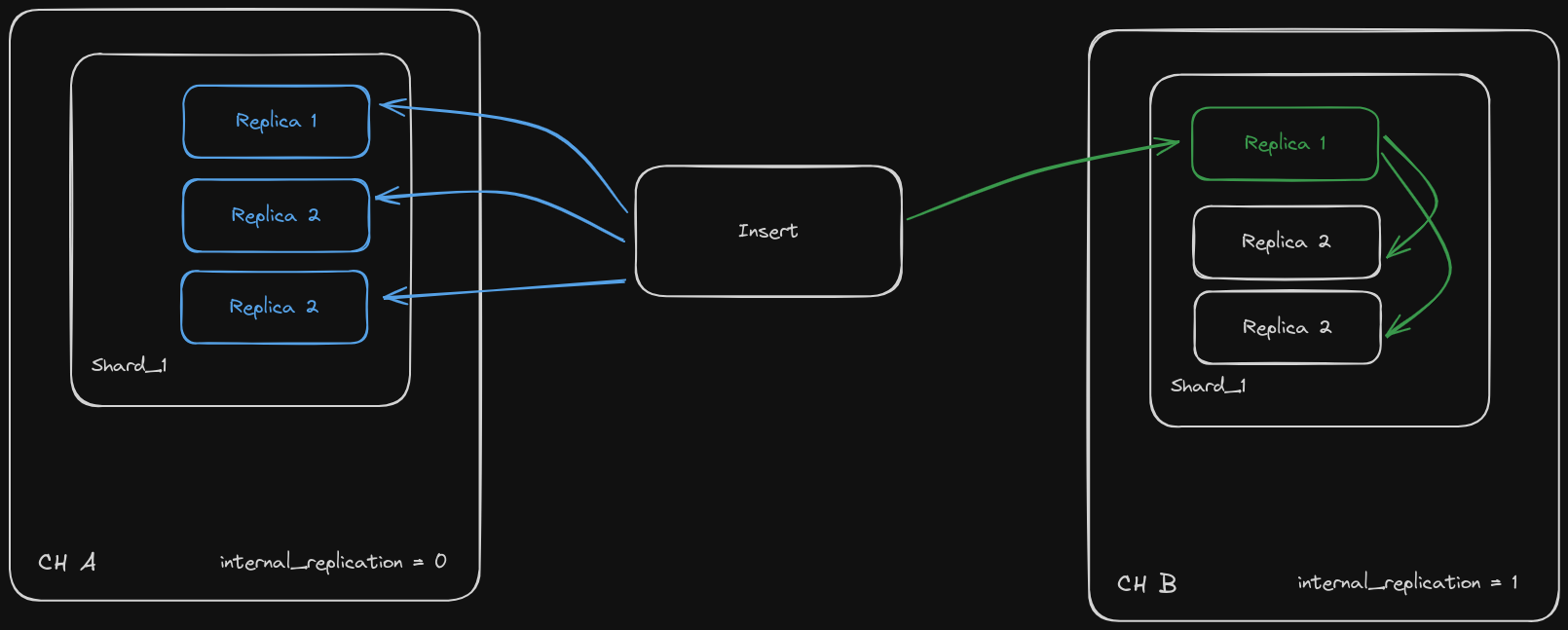
Simple example
Config
We have two ClickHouse clusters: CH-A and CH-B:
For shards of CH-A we set internal_replication = false:
...
<shard>
<internal_replication>false</internal_replication>
<replica>
...
And for shards of CH-B we set internal_replication = true:
...
<shard>
<internal_replication>true</internal_replication>
<replica>
...
You can use my clickhouse-cluster-compose project to deploy this example. You just need to change the setting in config/clickhouse/config.d/remote_servers.xml file.
Table sutrucure and all other settings will be the same for both clusters, difference only in internal_replication setting.
Create tables:
CREATE TABLE table_local ON CLUSTER '{cluster}'
(
`num` Int32
)
ENGINE = MergeTree
ORDER BY num
;
CREATE OR REPLACE TABLE table_distr ON CLUSTER '{cluster}' AS table_local
ENGINE = Distributed('{cluster}', default, table_local, rand())
;
Insert data:
On one of replicas of both clusters execute:
INSERT INTO table_distr VALUES (1)(2)(3)(4);
Count inser queries:
Now we can check how many insert queries were executed on each replica:
SELECT count()
FROM remote('clickhouse-01-01', 'system.query_log')
WHERE query_kind = 'Insert';
SELECT count()
FROM remote('clickhouse-01-02', 'system.query_log')
WHERE query_kind = 'Insert';
On CH-A (internal_replication = false) we have:
┌─count()─┐
│ 2 │
└─────────┘
┌─count()─┐
│ 2 │
└─────────┘
On CH-B (internal_replication = true) the result is:
┌─count()─┐
│ 2 │
└─────────┘
┌─count()─┐
│ 0 │
└─────────┘
Conclusion
As you can see, CH-A has two insert queries for each replica, because the Distributed table replicates the data. And CH-B only has the insert queries for a single replica, that means we have the rows only on one replica. To replicate the data on other replicas we need to use Replicated table engines. When one of the table replicas receives the write, it will be replicated to the other replicas throw ClickHouse Keeper.